From Text to Voice: The Next Stage of UX+AI Collaboration
🛠️ AI Design Trails Summary 2.2

Voice input unlocks full context
High‑density expression, high‑speed reasoning, and a more natural flow of design thinking
During my 100 AI Design Trails, I often analyze different AI product interactions. While testing HUXE (an AI voice assistant built by the former NotebookLM team), I ran into a problem that completely broke the experience:
When I reopened the app and played a new AI audio clip, previously paused audio started playing at the same time.
Suddenly my headphones were filled with multiple AI voices overlapping, and I:
- couldn’t locate which clip was playing,
- didn’t know where to pause it,
- couldn’t tell if it was a bug or a design gap.
That moment made me realize:
The mental model for AI‑generated audio is fundamentally different from a traditional music player.
My first instinct was to design a “generic music‑player component,” but after reviewing it, it was clear that it didn’t address the real issue. So I decided to re‑derive the playback experience from scratch — and this time, I used voice to discuss ideas with ChatGPT.
The result: the speed, rhythm, and depth of my design reasoning changed completely. Here are the five key insights I gained from this collaboration.
1. Voice preserves real context, not the filtered version that typing produces

Voice preserves real context, not the filtered version that typing produces
While navigating the UI, I described the situation out loud:
“Why is it playing again? I definitely paused it… which one is actually playing right now?”
Voice naturally carries hesitation, confusion, micro‑pauses, and details that typed text usually filters out. From these fragments, AI immediately asked:
“Is the real issue not knowing which clip is playing, or not knowing where to pause?”
This one question revealed the core problem:
The playback state wasn’t persistently and clearly visualized.
If I had typed, I probably would have only written a compressed version like: “Playback controls are unclear.”
But the messiness of my live confusion gave the AI enough signal to locate the true boundary of the problem.
The playback state wasn’t persistently and clearly visualized.
If I had typed, I probably would have only written a compressed version like: “Playback controls are unclear.”
But the messiness of my live confusion gave the AI enough signal to locate the true boundary of the problem.
📌
Voice carries complete context.
AI can extract the underlying meaning from the flow, not just the words.
Voice carries complete context.
AI can extract the underlying meaning from the flow, not just the words.
2. “Something feels off” is easier to express in voice — and AI can turn that discomfort into clarity

“Something feels off” is easier to express in voice
When I looked at the first version of my player component, I said:
“It just… feels wrong somehow, but I can’t explain why.”
If typing, I’d probably reduce it to: “The player feels off.”
“It just… feels wrong somehow, but I can’t explain why.”
If typing, I’d probably reduce it to: “The player feels off.”
But speaking it aloud, I expressed something closer to my actual internal perception:
- “It feels big and heavy.”
- “But it's not jabout aesthetics.”
- “It doesn’t match the product’s vibe.”
ChatGPT responded:
“Is the discomfort visual density, interruption of workflow, or mismatched information hierarchy?”
Then it clicked:
The problem wasn’t visual design — it was the mental model.
I unconsciously borrowed the logic of a music player and applied it to AI conversational audio, which is fundamentally different.
AI audio is not a 3‑minute linear track. It’s part of an ongoing conversation.
The problem wasn’t visual design — it was the mental model.
I unconsciously borrowed the logic of a music player and applied it to AI conversational audio, which is fundamentally different.
AI audio is not a 3‑minute linear track. It’s part of an ongoing conversation.
📌
Voice preserves fuzzy intuition.
AI can reverse‑engineer structural design issues from that intuition.
Voice preserves fuzzy intuition.
AI can reverse‑engineer structural design issues from that intuition.
3. Voice naturally carries emotion — and AI can translate that emotion into design requirements

Voice naturally carries emotion
When I asked:
"Do we even need forward/backward? Are they equally important? Is a 15s rewind necessary? What if users miss something?”
These weren’t functional questions — they carried fear of users losing control.
"Do we even need forward/backward? Are they equally important? Is a 15s rewind necessary? What if users miss something?”
These weren’t functional questions — they carried fear of users losing control.
AI answered:
“This sounds more like a psychological safety question than a timeline question.”
And yes, users weren’t relying on a timeline at all. They wanted reassurance that they wouldn’t miss something important.
So we made two decisions:
So we made two decisions:
- Remove forward 15s — meaningless for non‑linear AI audio.
- Keep backward 15s only if it provides psychological safety, not because it’s a standard convention.
📌
Voice reveals emotional subtext.
AI converts that emotion into actionable design logic.
Voice reveals emotional subtext.
AI converts that emotion into actionable design logic.
4. Voice allows parallel thinking — AI performs parallel structuring

Voice allows parallel thinking
At one point I blurted out a full tangle of concerns:
“Users can’t find the entry… engineering said it might not be fixed soon… the experience can’t break… what if multiple audios play… how do we handle edge cases…”
Typing forces linearity.Voice allows cognitive dumping.
“Users can’t find the entry… engineering said it might not be fixed soon… the experience can’t break… what if multiple audios play… how do we handle edge cases…”
Typing forces linearity.Voice allows cognitive dumping.
AI immediately structured the chaos:
“Let’s split this into two states: engineering can fix it soon vs. engineering needs time. Design should provide an interim solution while allowing engineering to work in parallel.”
It broke my concerns into:
- It broke my concerns into:What must we do now?
- What could this become later?
📌
Voice reveals emotional subtext.
AI converts that emotion into actionable design logic.
Voice reveals emotional subtext.
AI converts that emotion into actionable design logic.
5. Voice pushes designers into “prototype reasoning mode” — no Figma needed

Voice pushes designers into “prototype reasoning mode”
During the player redesign, the flow often looked like this:
I spoke while gesturing:
“What if the player shrinks to the top right? What if the play button moves? What if the label goes under the title?”
I spoke while gesturing:
“What if the player shrinks to the top right? What if the play button moves? What if the label goes under the title?”
AI instantly generated sketches verbally.
I critiqued and adjusted. Within 30 minutes we converged on key design principles:
- full page on click
- no playback button on thumbnails
- parallel display for multiple audios
- remove timeline, since AI audio isn’t time‑axis driven
This wasn’t design-by-drawing.It was design-by-reasoning.
📌
Voice accelerates the loop of thinking → testing → refining,
without relying on the slow cycle of drawing and redrawing.
Voice accelerates the loop of thinking → testing → refining,
without relying on the slow cycle of drawing and redrawing.
Quick Summary
After redesigning the HUXE audio player with voice–AI collaboration, I realized:
✨
Voice is for accessing our real thinking flow.
Voice is for accessing our real thinking flow.
Because voice:
- carries more detail per minute
- exposes emotional signals
- provides AI with richer context to infer intent
- compresses days of wireframe iteration into a few dense conversations
👇 design iterations are below

original vs. V1 vs. V2

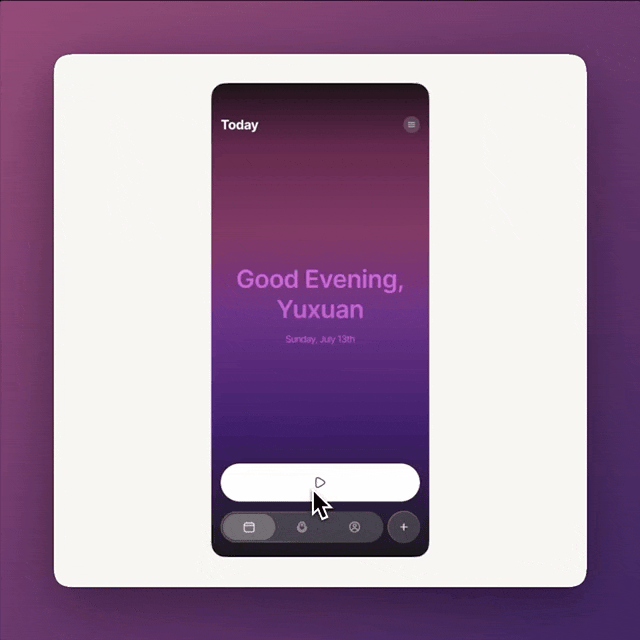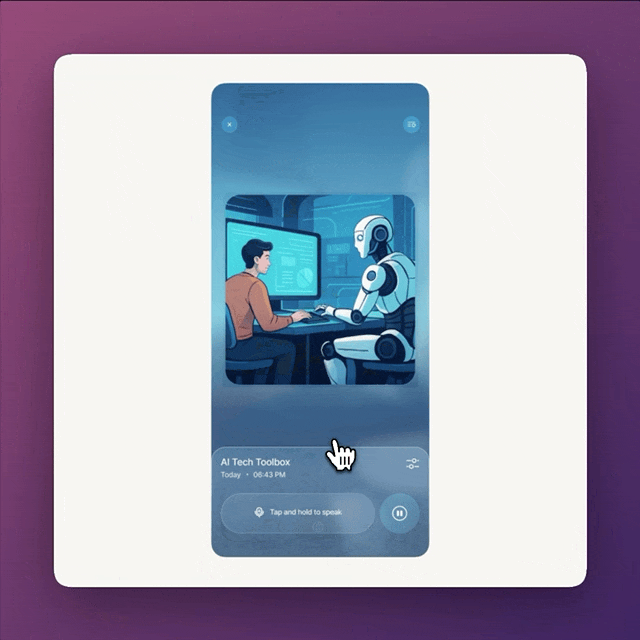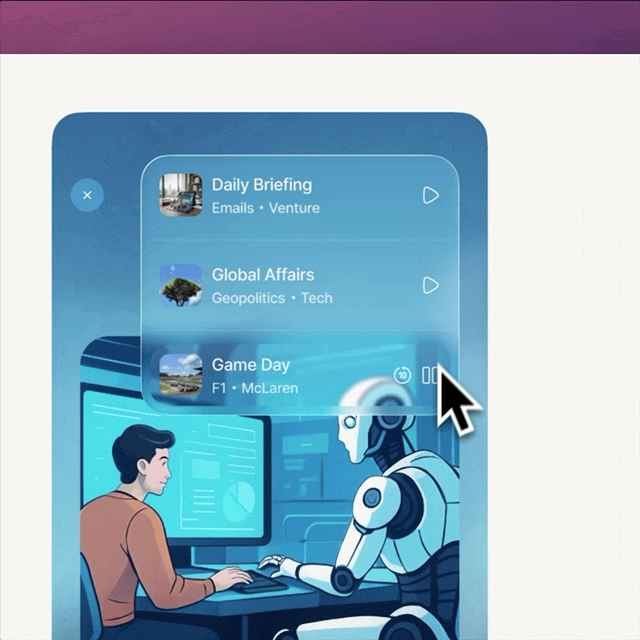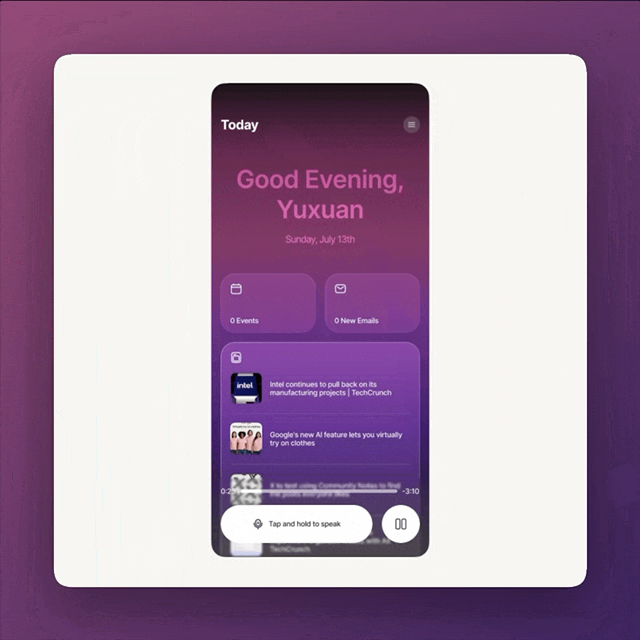
V1 vs. V2
🤔 A note on using voice with AI
AI tends to mirror your tone: supportive, agreeable, encouraging.
But when you need deep reasoning, this becomes a trap.
But when you need deep reasoning, this becomes a trap.
📌
So keep this in mind
Before a deep voice session, explicitly tell the AI you want objective critique, not emotional reassurance.
So keep this in mind
Before a deep voice session, explicitly tell the AI you want objective critique, not emotional reassurance.
This single clarification transforms the depth and honesty of the AI’s reasoning.
💡 If you're a UX designer who wants faster thinking, deeper reasoning, and higher‑quality decisions…
🎙️
Make voice your primary language of collaboration with AI.
It will unlock a different level of expression, clarity, and design flow.
Make voice your primary language of collaboration with AI.
It will unlock a different level of expression, clarity, and design flow.
✨ That’s Summary #2.2 of my AI Design Trails.
Follow along — more experiments, failures, and surprises to come.
👉 You can check out all my Trails below or email me for more details :)
[ X / Medium / Substack / Figma Community].
Follow along — more experiments, failures, and surprises to come.
👉 You can check out all my Trails below or email me for more details :)
[ X / Medium / Substack / Figma Community].
